

Discutons et de rien :)
You must log in or register to comment.
J’ai demandé à chatgpt via duck.ai de me rappeler la formule wget pour télécharger tous les documents pdf proposés sur une page internet.
Il m’a proposé ça :
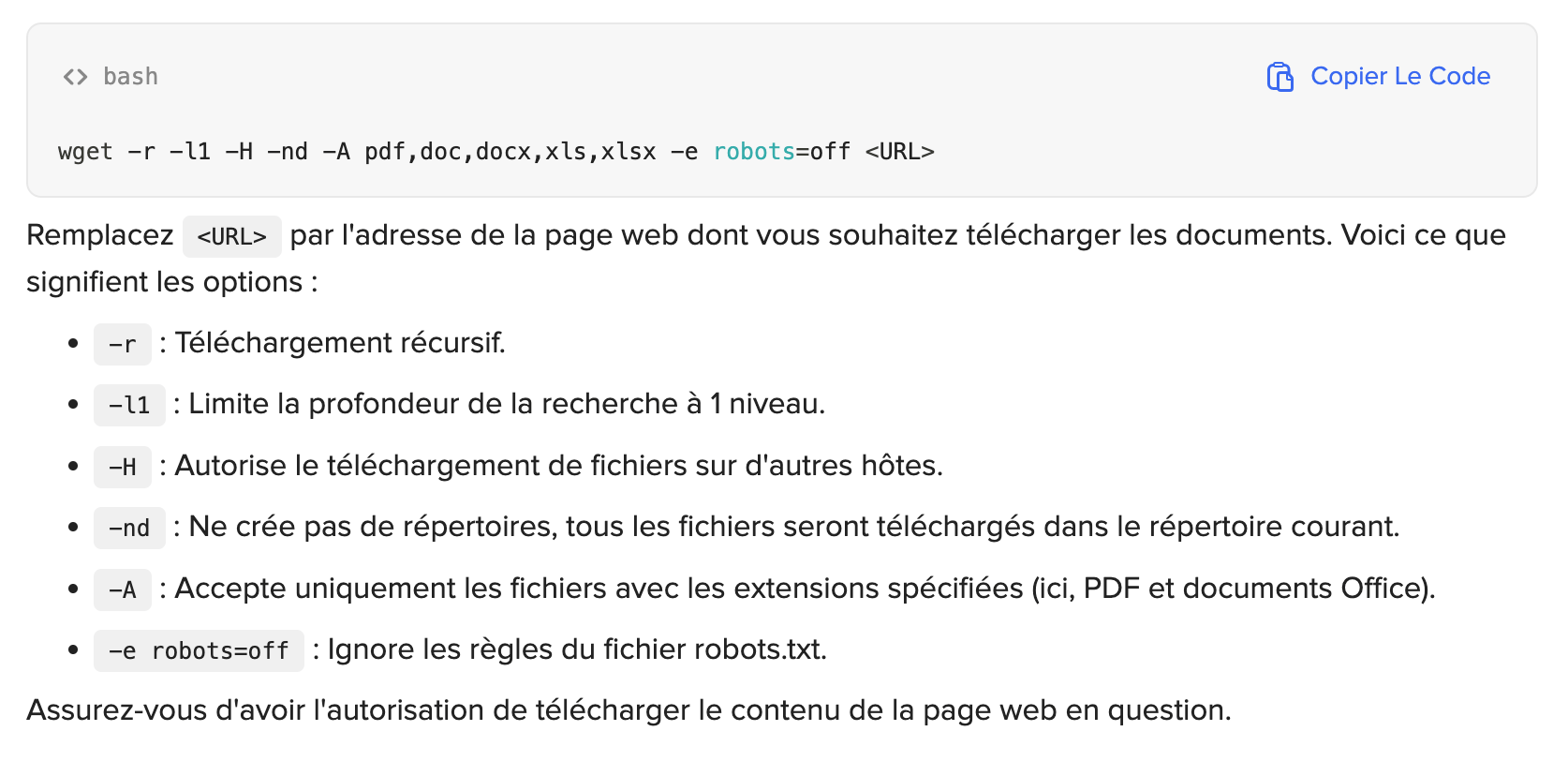
C’est normal la commande pour ignorer robots.txt ?
Ps : je trouve ça dingue déjà
- qu’il le propose
- et en plus par défaut (je ne lui avais aucunement spécifié que les documents concernés étaient visés par le fichier robot.txt ; ce n’était d’ailleurs pas le cas)
Assurez-vous d’avoir l’autorisation de télécharger le contenu de la page web en question.
Je ne m’y connais pas du tout, mais n’est-ce pas contradictoire avec le fait d’ignorer robots.txt ?
Pareil que toi, mais ça me semble bien contradictoire. Si je dis pas de bêtises, le document robots.txt est un document non contraignant, c’est plutôt une convention.
Le protocole d’exclusion des robots, plus connu sous le nom de robots.txt, est une convention visant à empêcher les robots d’exploration (web crawlers) d’accéder à tout ou une partie d’un site web.
Les robots peuvent ignorer votre fichier robots.txt, en particulier les robots malveillants qui crawlent les sites à la recherches de vulnérabilités ou d’adresses email
Le fichier robots.txt est un fichier accessible au public, ce qui signifie que n’importe qui peut voir ce que vous souhaitez ne pas faire indexer par les moteurs
Ah voilà, j’ai retrouvé le post d’@[email protected] (coucou!) à ce sujet : https://jlai.lu/post/16807807
According to Drew, LLM crawlers don’t respect robots.txt requirements and include expensive endpoints like git blame, every page of every git log, and every commit in your repository. They do so using random User-Agents from tens of thousands of IP addresses, each one making no more than one HTTP request, trying to blend in with user traffic.
Coucou !
Koin les gens !
Bonjour !
Bonjour ٩(◕‿◕。)۶
Tous les matins, cette discussion me fait penser à ça : Bonjour - la Belle et la Bête
- Bonjour !
- Bonjour ! Salut la famille !
- Bonjour !
- Bonjour ! Embrasse ta femme !
- Il m’faut six œufs !
- Tu veux nous ruiner !
- Je veux vivre autre chose que cette vie !!
Moi j’aime bien dire bonjour, c’est le début d’une nouvelle journée. Chaque jour on commence une nouvelle page 😄
Y a un peu de ça ha ha





