

2·
8 hours agoIf you have Coltrane in there, I must mention “A love supreme”
If you have Coltrane in there, I must mention “A love supreme”

Hey that’s Jamie Oliver’s PMC and not count binface PMC.

Depends on what you do with it. Synthetic data seems to be really powerful if it’s human controlled and well built. Stuff like tiny stories (simple llm-generated stories that only use the complexity of a 3-year olds vocabulary) can be used to make tiny language models produce sensible English output. My favourite newer example is the base data for AlphaProof (llm-generated translations of proofs in Math-Papers to the proof-validation system LEAN) to teach an LLM the basic structure of Mathematics proofs. The validation in LEAN itself can be used to only keep high-quality (i.e. correct) proofs. Since AlphaProof is basically a reinforcement learning routine that uses an llm to generate good ideas for proof steps to reduce the size of the space of proof steps, applying it yields new correct proofs that can be used to further improve its internal training data.
This is the Airbud defense, which is fitting for a flying dog
The official name for the driver of a Cybertruck is a cybercuck
Did not know that. But there’s still gotta be some legacy code that is not really needed for humans somewhere. Perhaps some stuff in our genes that’s just there and no one really knows what good it does, like some obscure dependency in conputer code
Also got them, but never knew they advertised. Got expensive designer glasses from a small German shop, but needed some replacement for traveling and something for sports with my new measurements. So I ordered something cheap of Zenni. My replacement glasses were 50€ glassesvfrom Zenni that I liked more than the expensive ones in the end. So now I am mostly wearing those.
Do they grind the news media executives into a fine general purpose powder (like Torgo’s executive powder) or where does the name come from?

Seafile. It’s already on my phone when I want it there.

No idea how Fortnite works. But can you (realistically) use the Cybertruck to cut off your enemies fingers with it’s automatic doors.
But it can also go horribly wrong. For example, Cameron called the Brexit referendum without wanting Brexit, which did not go as planned

That’s not my department said Wernher von Braun
Well. The folk punks always knew that we all are just compost in training.
I did move within the EU for studying and for work and it was generally a good experience and I would do it again. Am German and have been in Ireland for studying and lived in the Netherlands and Slovenia for work (although never longer than for one year).
Smithers … You … Are … Really … Good … At… Turning me on.
Nightmares beyond human comprehension like something out of a video game character creator with lots of liberty but even weirder and then probably the default settings again.
It seems like it’s been a while since you last checked in with BONTO! We’d love your feedback on how we can improve. Log in to get started!





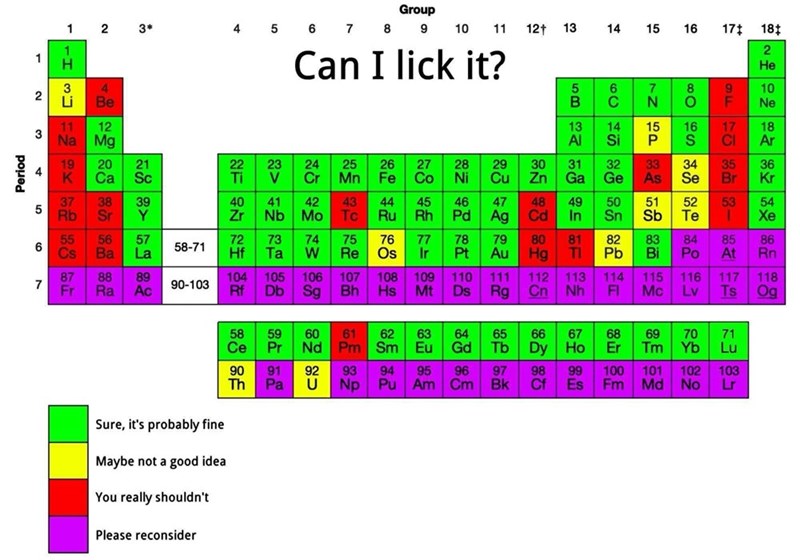{kind=link}
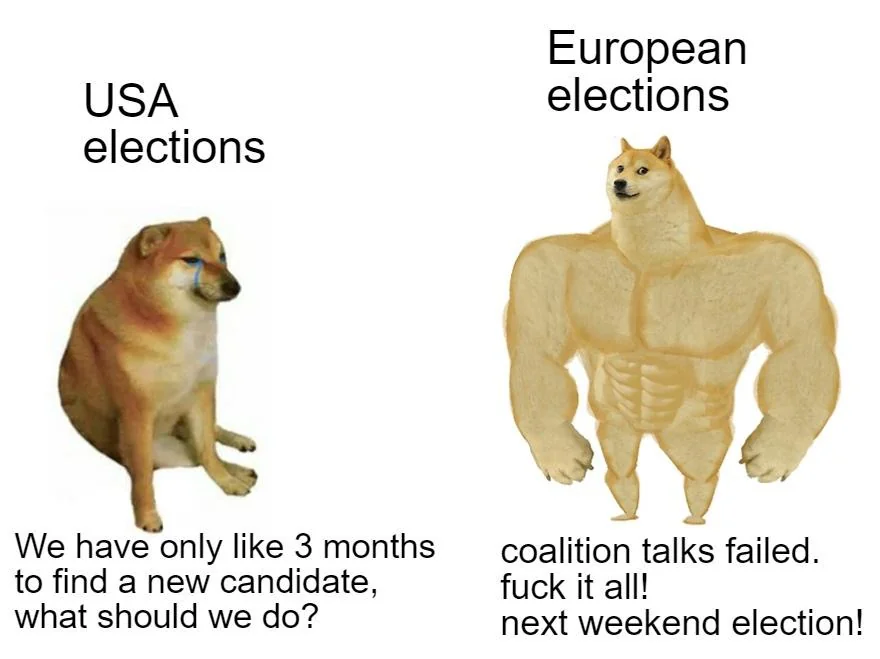{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
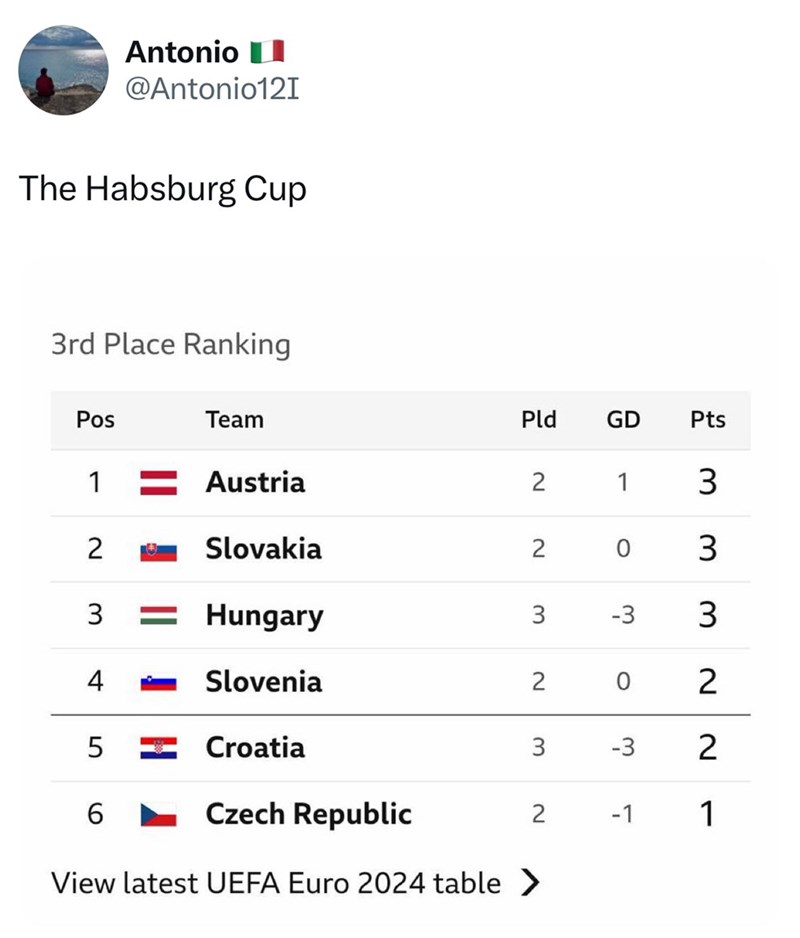{kind=link}
{kind=link}
Uncultured seeming option, but I nevertheless use it often to read and like it: Lo-fi beats to relax and study to playlist.