(fair warning - I go a little overboard on the examples. Sorry for the length.)
No idea on the details, but apparently it’s more efficient for multithreaded reading/writing.
I guess that you could have a few threads reading the file data at once into memory. While one CPU core reads the first 50% of the file, and second can be reading in the second 50% (though I’m sure it’s not actually like that, but as a general example). Image compression usually works some form of averaging over an area, so figuring out ways to chop the area up, such that those patches can load cleanly without data from the adjoining patches is probably tricky.
I found this semi-visual explanation with a quick google. The image in 3.4 is kinda what I’m talking about. In the end you need equally sized pixels, but during compression, you’re kinda stretching out the values and/or mapping of values to pixels.
Not an actual example, but highlights some of the problems when trying to do simultaneous operations…
Instead of pixels 1, 2, 3, 4 being colors 1.1, 1.2, 1.3, 1.4, you apply a function that assigns the colors 1.1, 1.25, 1.25, 1.4. You now only need to store the values 1.1, 1.25, 1.4 (along with location). A 25% reduction in color data. If you wanted to cut that sequence in half for 2 CPUs with separate memory blocks to read at once, you lose some of that optimization. Now CPU1 and CPU2 need color 1.25, so it’s duplicated. Not a big deal in this example, but these bundles of values can span many pixels and intersect with other bundles (like color channels - blue can be most efficiently read in 3 pixels wide chunks, green 2 pixel wide chunks, and red 10 pixel wide chunks). Now where do you chop those pixels up for the two CPUs? Well, we can use our “average 2 middle values in 4 pixel blocks” approach, but we’re leaving a lot of performance on the table with empty or useless values. So, we can treat each of those basic color values as independent layers.
But, now that we don’t care how they line up, how do we display a partially downloaded image? The easiest way is to not show anything until the full image is loaded. Nothing nothing nothing Tada!
Or we can say we’ll wait at the end of every horizontal line for the values to fill in, display that line, then start processing the next. This is the old waiting for the picture to slowly load in 1 line at a time cliche. Makes sense from a human interpretation perspective.
But, what if we take 2D chunks and progressively fill in sub-chunks? If every pixel is a different color, it doesn’t help, but what about a landscape photo?
First values in the file: Top half is blue, bottom green. 2 operations and you can display that. The next values divide the halves in half each. If it’s a perfect blue sky (ignoring the horizon line), you’re done and the user can see the result immediately. The bottom half will have its values refined as more data is read, and after a few cycles the user will be able to see that there’s a (currently pixelated) stream right up the middle and some brownish plant on the right, etc. That’s the image loading in blurry and appearing to focus in cliche.
All that is to say, if we can do that 2D chunk method for an 8k image, maybe we don’t need to wait until the 8k resolution is loaded if we need smaller images for a set. Maybe we can stop reading the file once we have a 1024x1024 pixel grid. We can have 1 high res image of a stoplight, but treat is as any resolution less than the native high res, thanks to the progressive loading.
So, like I said, this is a general example of the types of conditions and compromises. In reality, almost no one deals with the files on this level. A few smart folks write libraries to handle the basic functions and everyone else just calls those libraries in their paint, or whatever, program.
Oh, that was long. Um, sorry? haha. Hope that made sense!


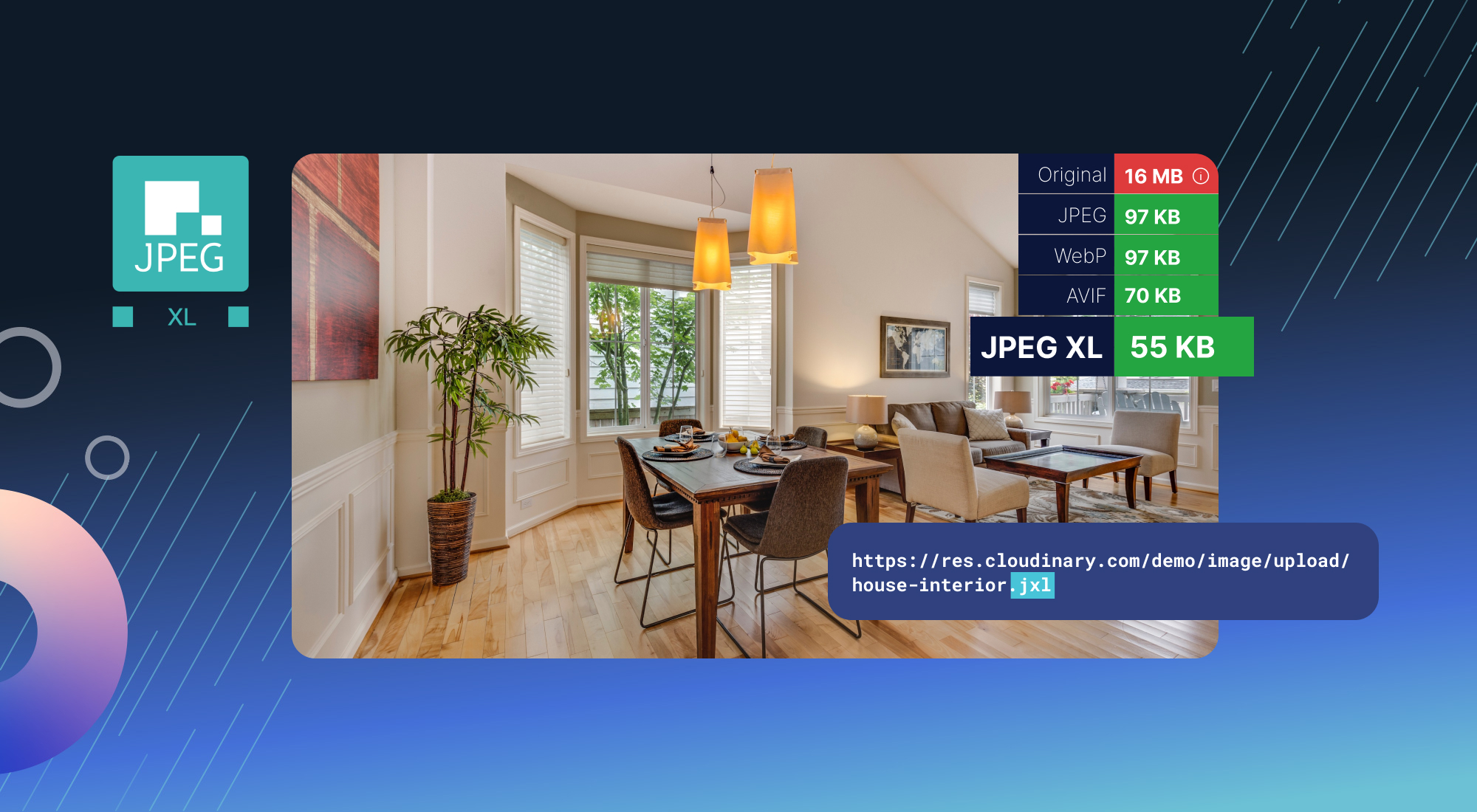
(fair warning - I go a little overboard on the examples. Sorry for the length.)
No idea on the details, but apparently it’s more efficient for multithreaded reading/writing.
I guess that you could have a few threads reading the file data at once into memory. While one CPU core reads the first 50% of the file, and second can be reading in the second 50% (though I’m sure it’s not actually like that, but as a general example). Image compression usually works some form of averaging over an area, so figuring out ways to chop the area up, such that those patches can load cleanly without data from the adjoining patches is probably tricky.
I found this semi-visual explanation with a quick google. The image in 3.4 is kinda what I’m talking about. In the end you need equally sized pixels, but during compression, you’re kinda stretching out the values and/or mapping of values to pixels.
Not an actual example, but highlights some of the problems when trying to do simultaneous operations…
Instead of pixels 1, 2, 3, 4 being colors 1.1, 1.2, 1.3, 1.4, you apply a function that assigns the colors 1.1, 1.25, 1.25, 1.4. You now only need to store the values 1.1, 1.25, 1.4 (along with location). A 25% reduction in color data. If you wanted to cut that sequence in half for 2 CPUs with separate memory blocks to read at once, you lose some of that optimization. Now CPU1 and CPU2 need color 1.25, so it’s duplicated. Not a big deal in this example, but these bundles of values can span many pixels and intersect with other bundles (like color channels - blue can be most efficiently read in 3 pixels wide chunks, green 2 pixel wide chunks, and red 10 pixel wide chunks). Now where do you chop those pixels up for the two CPUs? Well, we can use our “average 2 middle values in 4 pixel blocks” approach, but we’re leaving a lot of performance on the table with empty or useless values. So, we can treat each of those basic color values as independent layers.
But, now that we don’t care how they line up, how do we display a partially downloaded image? The easiest way is to not show anything until the full image is loaded. Nothing nothing nothing Tada!
Or we can say we’ll wait at the end of every horizontal line for the values to fill in, display that line, then start processing the next. This is the old waiting for the picture to slowly load in 1 line at a time cliche. Makes sense from a human interpretation perspective.
But, what if we take 2D chunks and progressively fill in sub-chunks? If every pixel is a different color, it doesn’t help, but what about a landscape photo?
First values in the file: Top half is blue, bottom green. 2 operations and you can display that. The next values divide the halves in half each. If it’s a perfect blue sky (ignoring the horizon line), you’re done and the user can see the result immediately. The bottom half will have its values refined as more data is read, and after a few cycles the user will be able to see that there’s a (currently pixelated) stream right up the middle and some brownish plant on the right, etc. That’s the image loading in blurry and appearing to focus in cliche.
All that is to say, if we can do that 2D chunk method for an 8k image, maybe we don’t need to wait until the 8k resolution is loaded if we need smaller images for a set. Maybe we can stop reading the file once we have a 1024x1024 pixel grid. We can have 1 high res image of a stoplight, but treat is as any resolution less than the native high res, thanks to the progressive loading.
So, like I said, this is a general example of the types of conditions and compromises. In reality, almost no one deals with the files on this level. A few smart folks write libraries to handle the basic functions and everyone else just calls those libraries in their paint, or whatever, program.
Oh, that was long. Um, sorry? haha. Hope that made sense!
Yeah a bit confusing at times but overall very cool and informative, thanks so much!