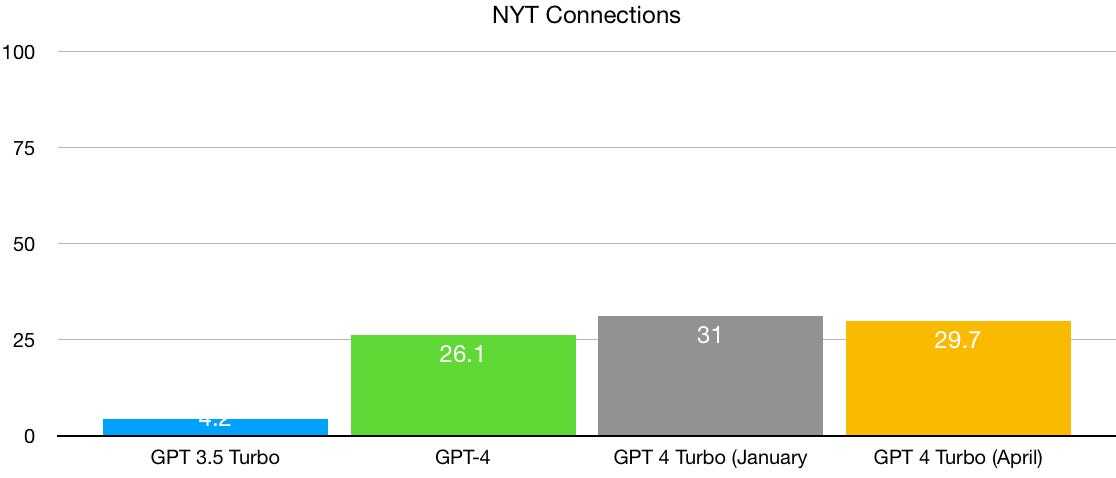
The conventional wisdom, well captured recently by Ethan Mollick, is that LLMs are advancing exponentially. A few days ago, in very popular blog post, Mollick claimed that “the current best estimates of the rate of improvement in Large Language models show capabilities doubling every 5 to 14 months”:

I mean, LLMs already are prime time. They’re capable of tons of stuff. Even if they don’t gain a single new ability from here onward they’re still revolutionary and their impact is only just becoming apparent. They don’t need to become AGI.
So speculating that they “may never be ready for prime time” is just dumb. Perhaps he’s focused on just one specific application.