Basically scripts you can run on the fly to pull calculated data. You can (mostly) treat them like tables themselves if you create them on the server.
So if you have repeat requests, you can save the view with maybe some broader parameters and then just SELECT * FROM [View_Schema].[My_View] WHERE [Year] = 2023 or whatever.
It can really slow things down if your views start calling other views in since they’re not actually tables. If you’ve got a view that you find you want to be calling in a lot of other views, you can try to extract as much of it as you can that isn’t updated live into a calculated table that’s updated by a stored procedure. Then set the stored procedure to run at a frequency that best captures the changes (usually daily). It can make a huge difference in runtime at the cost of storage space.
It can really slow things down if your views start calling other views in since they’re not actually tables
They can be in some cases! There’s a type of view called an “indexed” or “materialized” view where the view data is stored on disk like a regular table. It’s automatically recomputed whenever the source tables change. Doesn’t work well for tables that are very frequently updated, though.
Having said that, if you’re doing a lot of data aggregation (especially if it’s a sproc that runs daily), you’d probably want to set up a separate OLAP database so that large analytical queries don’t slow down transactional queries. With open-source technologies, this is usually using Hive and Presto or Spark combined with Apache Airflow.
Also, if you have data that’s usually aggregated by column, then a column-based database like Clickhouse is usually way faster than a regular row-based database. These store data per-column rather than per-row, so aggregating one column across millions or even billions of rows (eg average page load time for all hits ever recorded) is fast.
A view is a saved query that pretends it’s a table. It doesn’t actually store any data. So if you need to query 10 different tables, joining them together and filtering the results specific ways, a view would just be that saved query, so instead of “SELECT * FROM (a big mess of tables)” you can do “SELECT * FROM HandyView”


{kind=link}
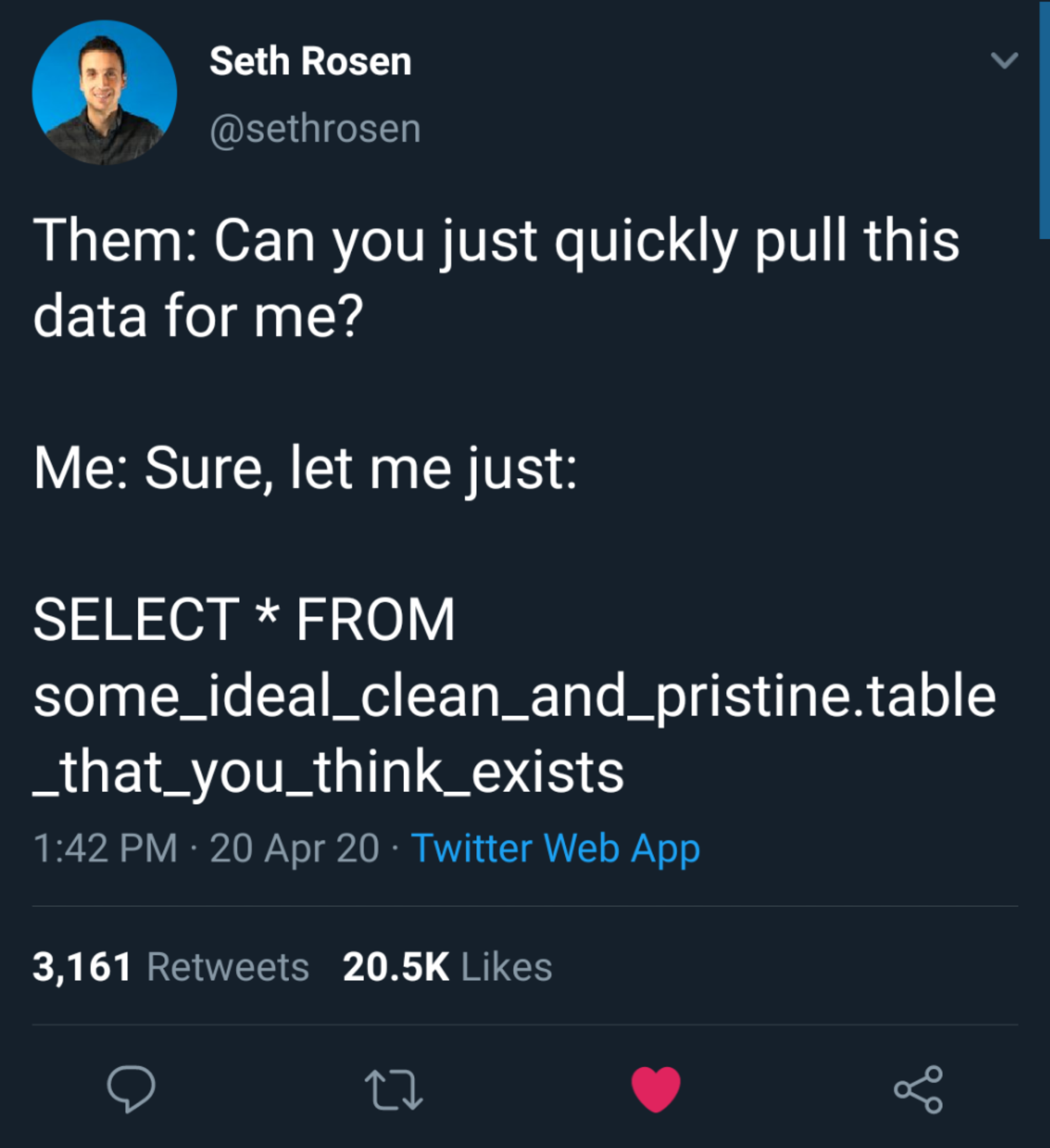
Somebody tell this dude about views.
If they existed for tons of random usecases. When was the last time you created views for “just in case someone asks” situations?
So my work is archaic and doesn’t even use SQL. What are views?
Basically scripts you can run on the fly to pull calculated data. You can (mostly) treat them like tables themselves if you create them on the server.
So if you have repeat requests, you can save the view with maybe some broader parameters and then just SELECT * FROM [View_Schema].[My_View] WHERE [Year] = 2023 or whatever.
It can really slow things down if your views start calling other views in since they’re not actually tables. If you’ve got a view that you find you want to be calling in a lot of other views, you can try to extract as much of it as you can that isn’t updated live into a calculated table that’s updated by a stored procedure. Then set the stored procedure to run at a frequency that best captures the changes (usually daily). It can make a huge difference in runtime at the cost of storage space.
They can be in some cases! There’s a type of view called an “indexed” or “materialized” view where the view data is stored on disk like a regular table. It’s automatically recomputed whenever the source tables change. Doesn’t work well for tables that are very frequently updated, though.
Having said that, if you’re doing a lot of data aggregation (especially if it’s a sproc that runs daily), you’d probably want to set up a separate OLAP database so that large analytical queries don’t slow down transactional queries. With open-source technologies, this is usually using Hive and Presto or Spark combined with Apache Airflow.
Also, if you have data that’s usually aggregated by column, then a column-based database like Clickhouse is usually way faster than a regular row-based database. These store data per-column rather than per-row, so aggregating one column across millions or even billions of rows (eg average page load time for all hits ever recorded) is fast.
A view is a saved query that pretends it’s a table. It doesn’t actually store any data. So if you need to query 10 different tables, joining them together and filtering the results specific ways, a view would just be that saved query, so instead of “SELECT * FROM (a big mess of tables)” you can do “SELECT * FROM HandyView”
Predefined queries that you can interact with like another table more or less
deleted by creator